Data Supply Platform
Quintin Stephenson. 9 May 2022
Country: Australia
Summary
It’s all about data ownership and control
Every organisation wants better control over their incoming data from external suppliers and the distribution there of to various systems within the enterprise. This is especially case in situations where the destination systems are 3rd party owned.
In this example, an Akkodis customer in the Public Sector in Australia approached us with a data challenge.
The Challenge
The client receives files from numerous sources ever month, which all go through intensive manual processes to then load into a core bespoke developed business application. This application then performs various evaluations and calculation on the data.
They found that this core system and supporting manual processes were aging and expensive to manage and maintain. They looked at cost effect alternatives and suppliers of similar systems around the world and soon realized they had a need to exercise greater control and ownership over this data as they started looking with the external 3rd party solutions.
The data comes in various flat file formats (position notation files, CSV files, XML, JSON) and unstructured in the form of PDF or image files. The data were transported/transferred in files using old methods such as email, or dropping files into shared file stores, which both have security issues.
The Solution
The client was not only looking for an ETL tool, but rather something that could work as a hub to take data from any approved relevant source, then validate and transform and distribute it to various systems throughout the organisation.
The Result
Through working with Akkodis, our client now has a highly configurable, scalable, cost-effective solution comprising of 10 Lambda functions (and growing). This solution breaks the business logic into smaller SOA components within one part of the overall business function. The bigger solution can be broken into three distinctive area:
- User Registration
- Application Usage where users upload files. This also includes Restful services the client’s partner user can execute to upload files/data without logging into a UI
- The Propagator
User Registration
This part of the application deals with user registration only. It allows user partially self-register. Internal users can register their intent to use the application through using their AD FS single sign credentials.
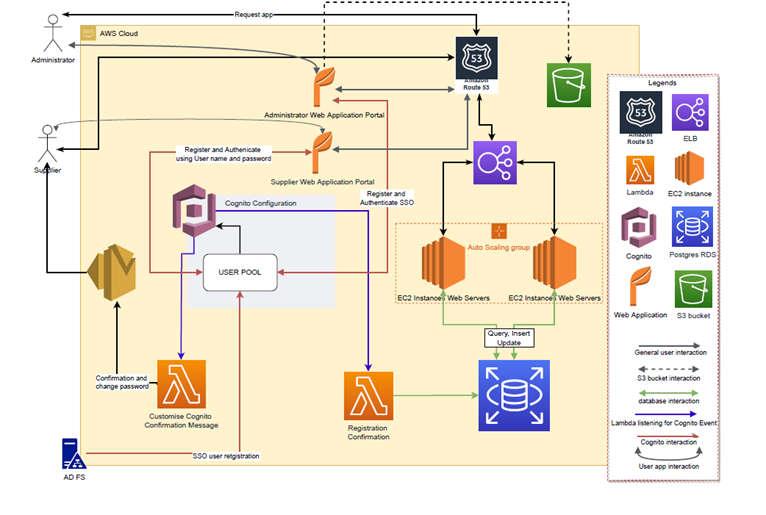
Notes:
- The Cognito USER POOL is setup to contain 2 sources:
- AD FS, these users are used for the Administration Web Application Portal only and is used to perform SSO styled logins. Cognito views these users as external.
- Locally Registered user, these users are used to logon into the Supplier Web Application portal (Supplier platform) and manually register their credentials.
- Both application portals are angular web applications that interact with java restfully services all originating from Wildfly web containers running on EC2 instances using the same domain.
- Files are sent to the S3 bucket via a pre-signed URL generated via a restful webservice.
Application Usage
Once a user is approved and begins to use the application as a supplier of data, they will be able to upload files for extraction and processing. They only execute high responsive restful services that will present a positive and informative experience.
Once the file has been uploaded, SQS queued Lambdas are woken up and an extraction, validation and if required a transformation is performed before its dataset is posted to a submitted state. The validation lambda scales horizontally to validate sets of 1,000 records defined via the SQS queueing mechanism.
Admin users will be able to monitor and manually amend data, as well as manage various aspects of their supplier users.
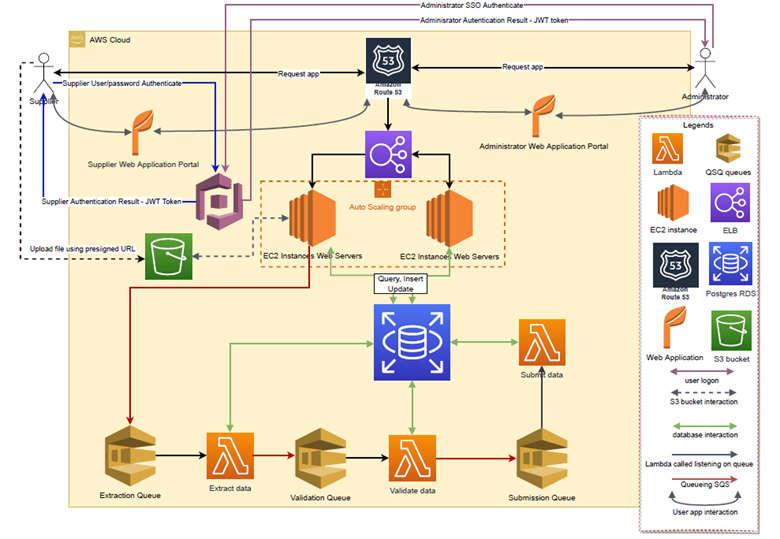
Notes on diagrams:
- There are no dead letter queues for this part of the application. The reason is that errors will be caught on the application screens.
- Both application portals are angular web applications that interact with java restfully services all originating from Wildfly web containers running on EC2 instances using the same domain.
- Files are sent to the S3 bucket via a pre-signed URL, which is generated via a restful webservice.
The Propagator
This is a completely serverless solution. This part of the solution sends data of files to the predetermined locations. Destinations for this data currently can be one of the following: file store, a restful web service, a database.
All the intelligence of what propagation actions are to be taken against a dataset are defined in a set of RDS table and are used as lookups by each Lambda involved. These definitions allow a single dataset to have multiple propagation definitions containing destinations, extracted values and data format (csv, xml, json).
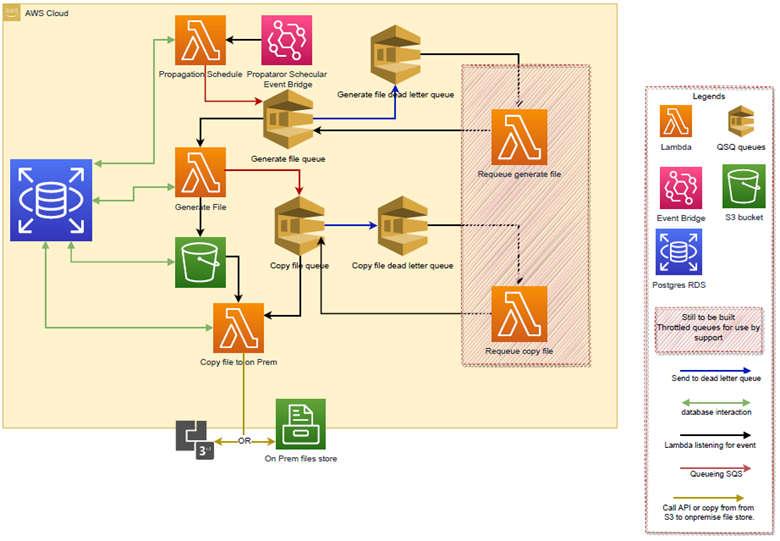
- Each lambda does one action only.
- Should a lambda that is being executed from a queue (SQS) fail 3 attempts of execution, the message will fail over to the dead letter queue.
- Once a message is delivered a dead letter queue, a CloudWatch metric sends an email to support notifying them to investigate.
- The Lambdas that are waiting on the dead letter queues are permanently throttled. They are only to be opened by an internal services support team member once they have investigated and resolved the issue for all messages in the queue. The lambda will then requeue the messages in queue where the messages came from for processing.
Results
This solution resulted in an efficient and cost-effective processing service, that required minimal management overhead. Our maintenance and management will be to update the Lambda Runtime(s) and our code base (Node.JS, Java) when language updates require modification, and manage our client-side JavaScript library dependencies such as Angular.
The delivery was driven from CloudFormation Templates, stored in CodeCommit, and deployed across environments from development to production using DevOps approaches. Therefore, maintenance and updates over time can be repeatedly and reliably re-deployed in the future.