Continuous Integration and Automated Deployment with Personal and Shared Environments
Siddharth Malani. 03 September 2021
Country: Australia
The Scenario
An Akkodis client in the resources sector uses machine learning to deliver a capability that helps improve the downstream processing of their product. Instead of having development environments for geoscientists that are running on local desktops and laptops, the customer wanted to make use of automatically generated, production like environments, to facilitate further investigation, development and delivery of the machine learning models, data pipelines, workflows, and configuration in the cloud environment.
The aim of using the AWS (Amazon Web Services) Cloud was to give the customer the ability to dynamically create multiple deployment environments that were the same as production, allowing data sets, configuration, and other resources to be shared. Additional benefits included:
- Ability to scale down, or terminate these environments when no longer needed
- Deployed on demand, helping the rapid development of features and ML (Machine Learning) models
- Consistency in build, deployment, and test processes
- Traceability of code and versioning
- Environments for developers to test their code prior to merging into the project’s mainline repository.
The Solution
The customer imposed a few constraints on the solution, mandating the use of:
- Gitlab
- Terraform
- AWS
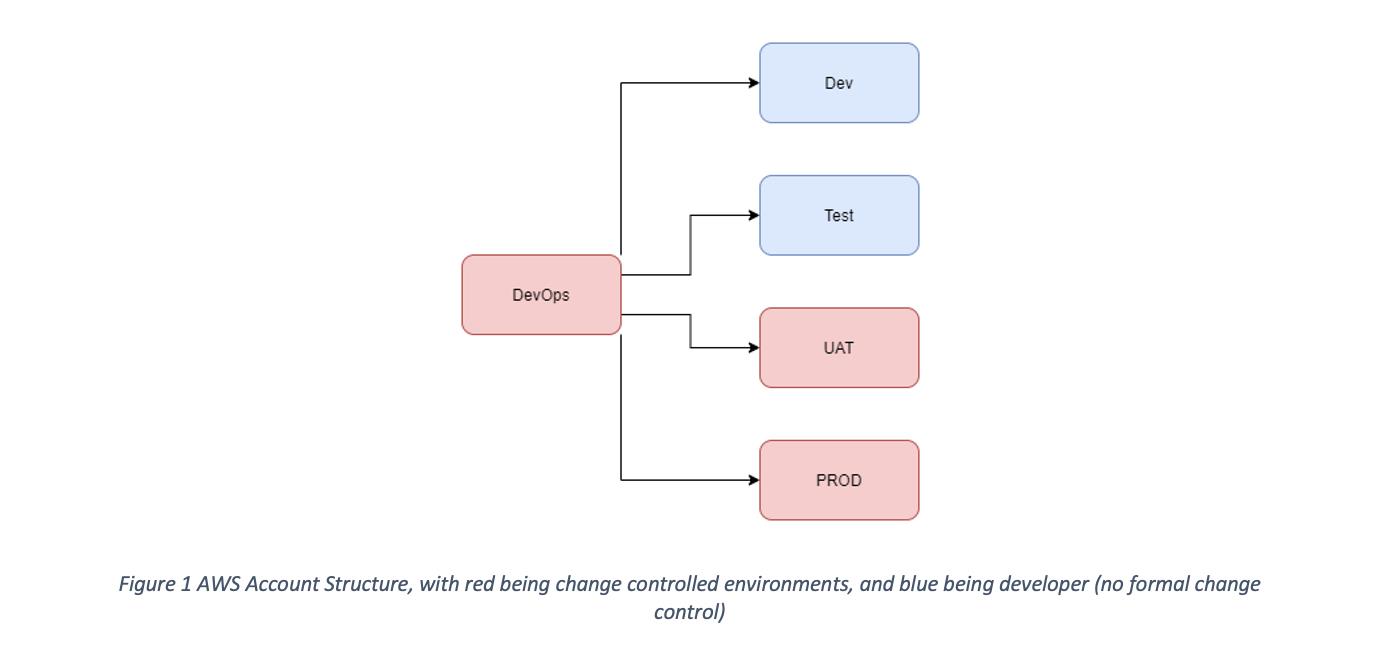
Environments
Recommended best practice is to separate your CI/CD pipelines from your workloads by utilizing separate AWS accounts for each. The “DevOps” account would have access to push to each of the workload accounts. Each separate workload account other than production was multi-tenanted to support more than one developer concurrently.
This structure is depicted in the below diagram:
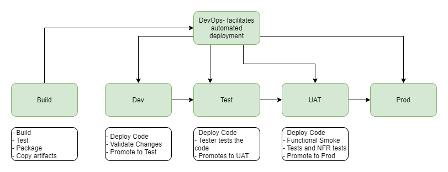
Code Deployment Pipeline
A uniform approach to the CI/CD pipeline was used:
Code gets pushed into the code repository Trigger code build Code is then deployed into the Development account When required, code gets promoted to higher environments. AWS CodePipeline is utilized to orchestrate the build and deployment process.
The built artifacts are stored in S3 and copied into a separate S3 bucket that is aligned to each deployable environment. S3 replication is used to copy the built artifacts into the relevant workload account, triggering a Lambda function to deploy to the respective microservice.
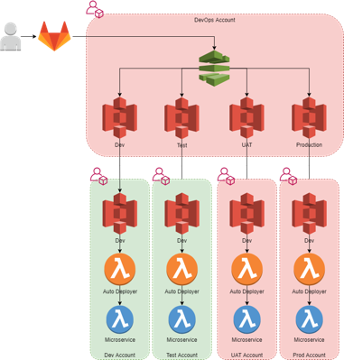
Infrastructure Deployment Pipeline
Gitlab and Terraform Cloud were used to deploy applications into AWS. All the AWS resources including AWS Lambda microservices, Step Functions, SageMaker, and managed databases (RDS) were defined in Terraform and deployed using Terraform Cloud into the AWS environments.

Each artifact that gets created has the checksum of the commit ID which triggered the build in its filename. The file that gets copied into S3 has the following naming convention:
<microservice-name>-<SHA>.zip The same checksum is used in the Terraform scripts as variables to deploy for full traceability.
Sandpit environments
The scripts used to perform the deployments to each environment are parameterized to support several parallel deployments or biomes (sub-environments). This approach enables the Geoscientists to build and test their code independently. These scripts are also optimized to share the same RDS instance and SageMaker endpoints. The SageMaker endpoints use multi-model deployments for cost-optimization.
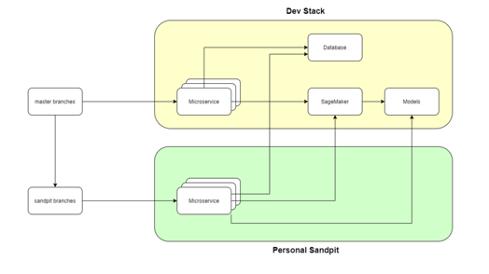
The Outcome
The solution uses Infrastructure as Code to define the environments, enabling rapid development and deployment of microservices and models across all the environments. The manual steps are reduced with the adoption of AWS CodePipeline and AWS CodeBuild, resulting in a consistent, simplified, repeatable developer experience.
The solution is also cost optimized and gives all the benefits required to the client under budget.